Designing the Right Question
Cloud.gov and the rest of GSA shared users. Our reporting didn’t.
For years, our annual Customer Loyalty Survey functioned as a required reporting ritual. Each program across GSA submitted its own invite list. The survey platform deduplicated participant emails so that no customer received more than one invitation to evaluate a GSA program.
On paper, the deduplication logic prevented spam.
In practice, it flattened a multi-product customer experience into siloed reports.
At the time, TTS operated at least ten distinct products (Login.gov, USA.gov, Search.gov, Cloud.gov, api.data.gov, Digital.gov, USWDS, 18F, the Centers of Excellence, the Digital Analytics Program, and more), many serving the same subset of federal agencies.
GSA and FAS, our parent orgs, operate a few dozen more, including the Public Buildings Service, which manages all of the federal workplaces. Nearly every federal agency interacts with GSA in some capacity. Yet our reporting reflected the org chart more than the lived customer experience. Federal agencies don’t experience GSA or TTS that way.
A capable agency technology team might use DAP for analytics, Login.gov for authentication, Cloud.gov for hosting infrastructure, Search.gov for site search, and USWDS for front-end patterns, often within the same project. From their perspective, they are working with teams at "GSA". From our reporting perspective, they were segmented into distinct product relationships.
The separated nature of GSA and TTS services forced agencies to “reintroduce” themselves to different corners of the same organization. The data segmentation made it harder for us to recognize shared customers and incentivized our programs to compete, not collaborate, in serving them.
Improving signal within the rules
First, I tailored our participation strategy to work inside the existing constraints.
I worked with our Customer Success team to curate short, targeted invite lists instead of exporting every email address we could find. I split Cloud.gov and Cloud.gov Pages into separate lists to reflect distinct usage patterns that I expected existed among our own customers. I rewrote optional questions to invite meaningful open-text responses instead of perfunctory checkboxes.
After the survey closed, the results were dramatic:
- 64% and 55% email open rates (org average: 4.5%)
- 85% and 88% survey completion rates (org average: 29%)
- 6,400+ words of open-text feedback — nearly eight times the prior year's engagement
- The lowest screen-out rate across all programs
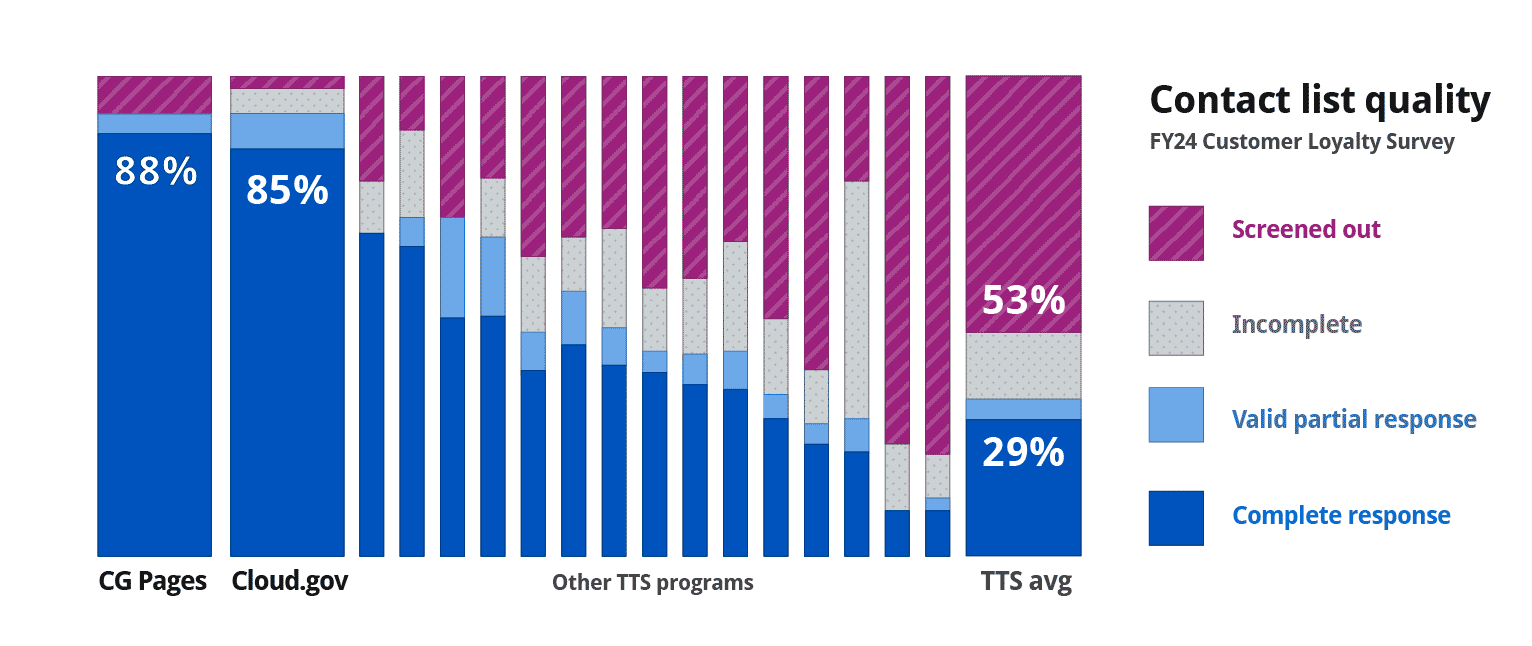
We contributed less than 1% of the total contact list while generating 7% of all responses. And we didn’t just increase total participation; we also increased signal density and response quality. But the more I worked within the system, the clearer the structural flaw became.
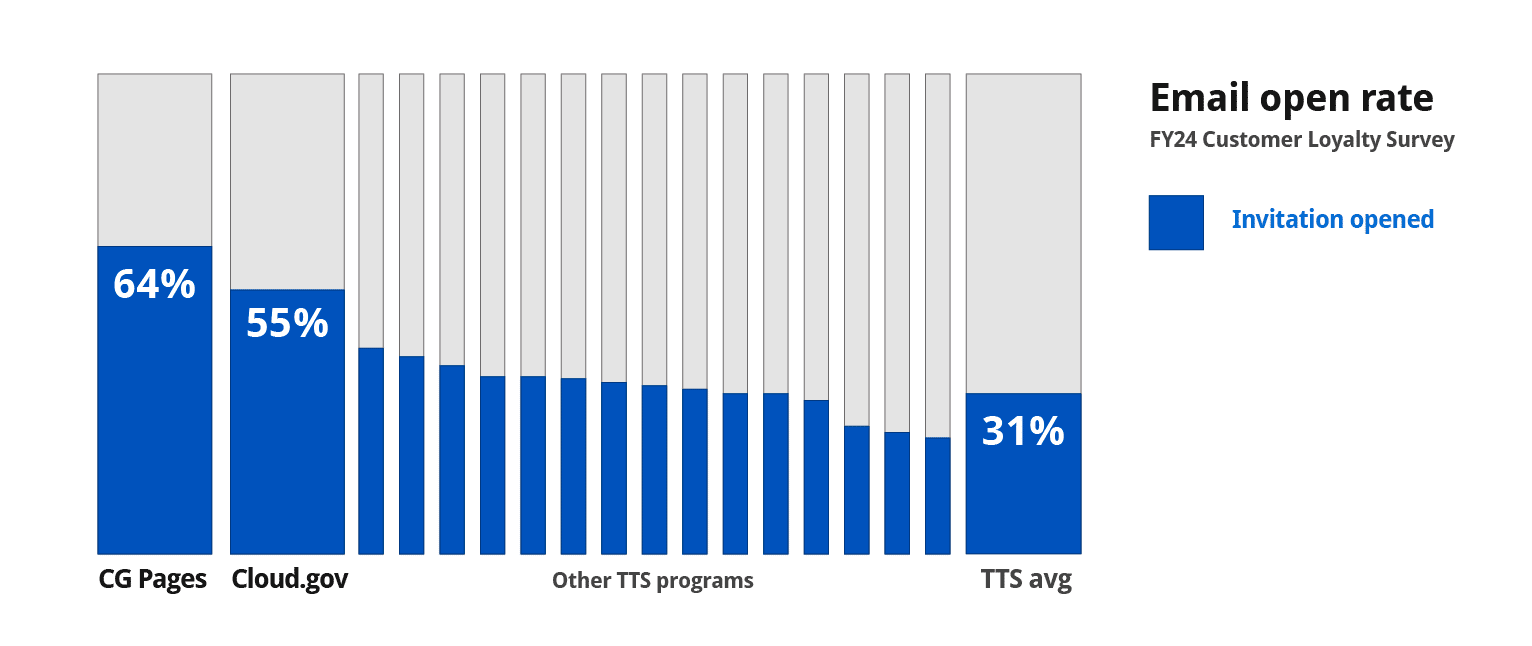
Cloud.gov’s results were exceptional — significantly higher than our sibling programs across multiple metrics relating to survey participation and customer service delivery. To be fair, I believe that reflects genuine customer satisfaction, which is supported by our follow-up questions. But I also realized how much our invite strategy and the survey’s deduplication rules amplified that signal.
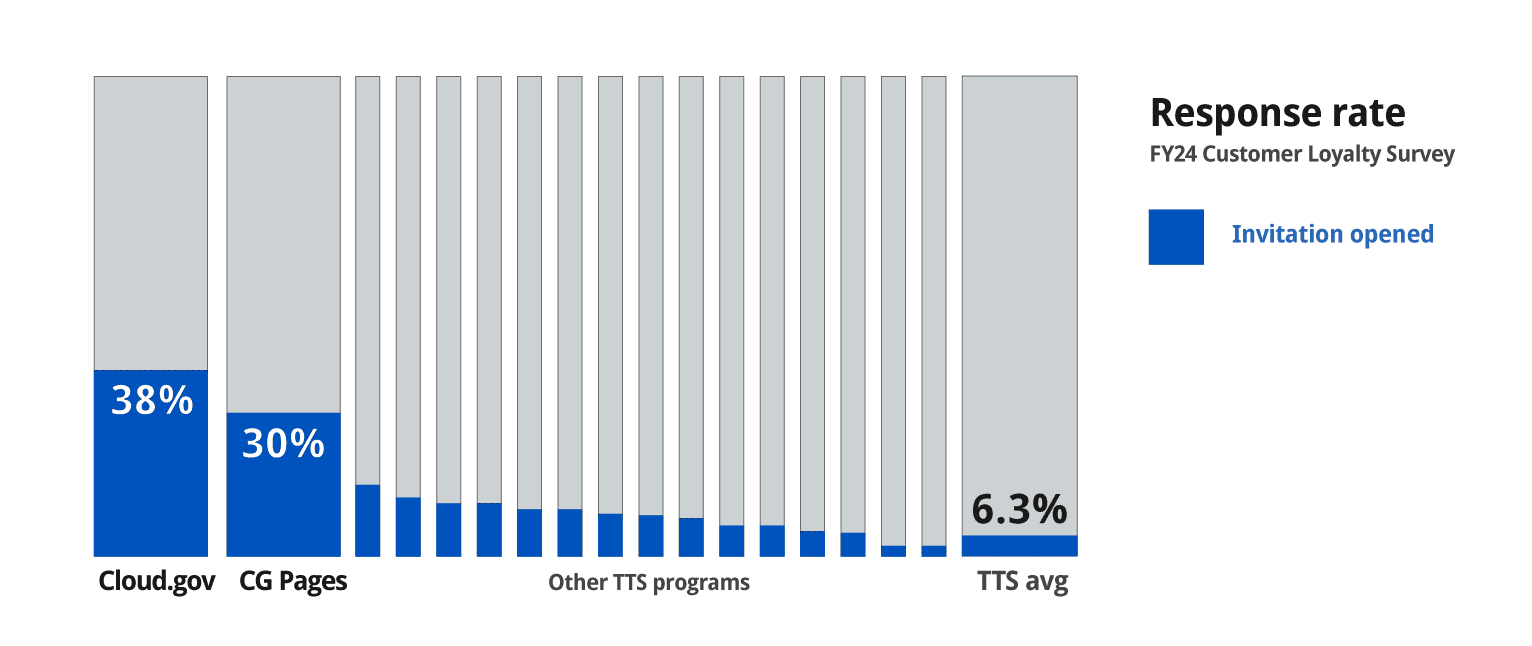
The methodology GSA had been working with for years ultimately incentivized programs to protect their own metrics. It rewarded teams that optimized for isolation rather than delivery accuracy. It's plausible that almost any program could dramatically outperform the org average, not because their customers were fundamentally different, but by strategically curating shorter invite lists.
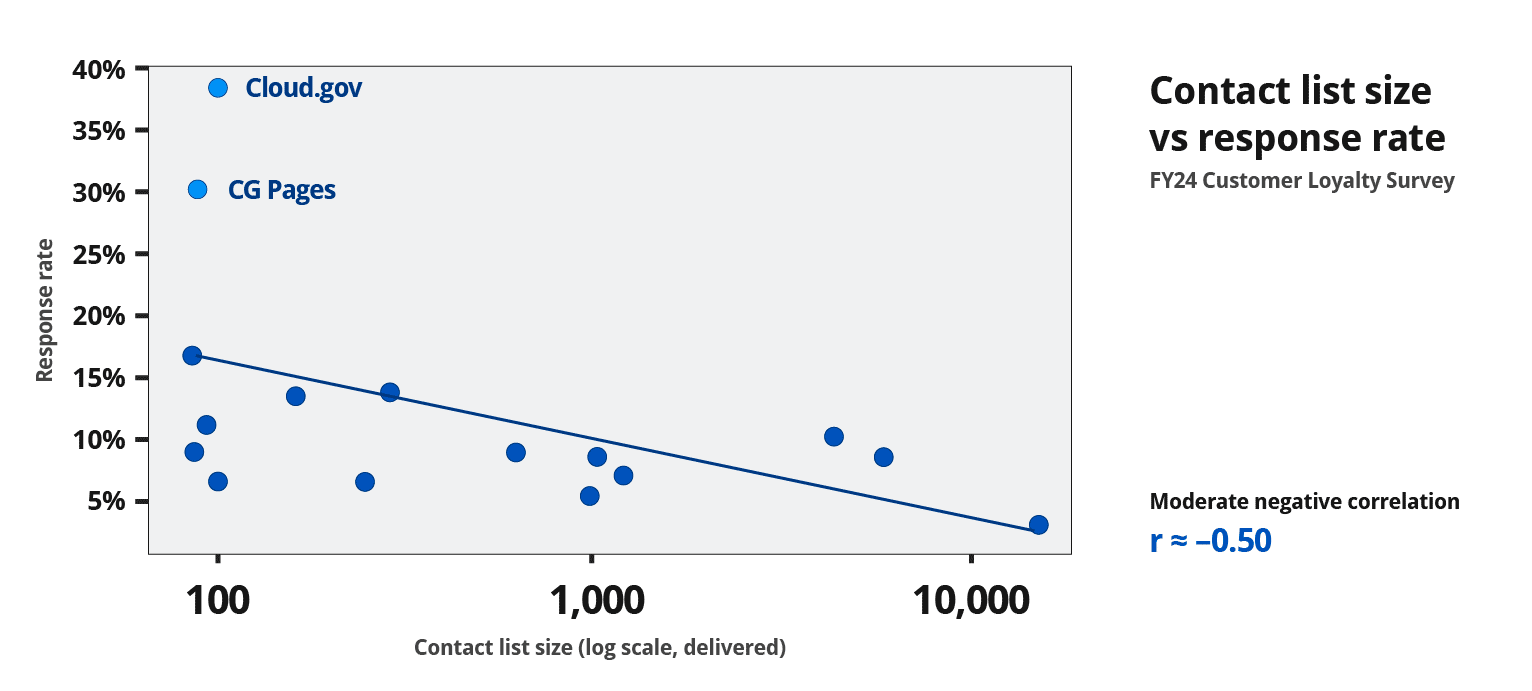
The structural distortion
Because programs submitted separate invite lists but shared many of the same agency customers, the deduplication logic meant a customer's responses were effectively assigned to a single product, even when they used several. When asked broad questions like, “What is your opinion of working with TTS?”, their response counted toward whichever specific product was allowed to keep that email in their contact list. And for years, every program has participated as instructed.
I'll admit that at first, I felt incentivized to game the system.
Then I realized I could fix it, so that other programs could benefit too.
While preparing for the survey roll-out, I explored collaborative solutions with the team administering the survey.
I asked whether identical emails or responses shared across lists could be flagged and shared between programs. I proposed allowing respondents to select which program they were responding about. I asked whether we could retroactively identify overlapping invitees just to track which customers we were losing to what sibling program.
Ultimately, the survey methodology was locked, and changes to either the invitation methodology or reporting were not negotiable. So while I still optimized our own participation, I saw an opportunity to test precisely how much context we were missing in this effort to prevent double-dipping.
Interrogating the instrument
If I couldn’t change the deduplication logic, I could test whether the underlying premise was true, and learn how much of a customer base we shared with our sibling programs at TTS at the same time.
I used one of our 5 optional survey questions to ask respondents how many other TTS programs they used. If customers truly experienced our programs independently, any overlap would be small, and I'd have been chasing one end of the bell curve.

The results were decisive:
- 80% of our Cloud.gov respondents used at least one other program.
- 30% reported using five or more.
We also got signal on which programs overlapped with certain customer segmentations:
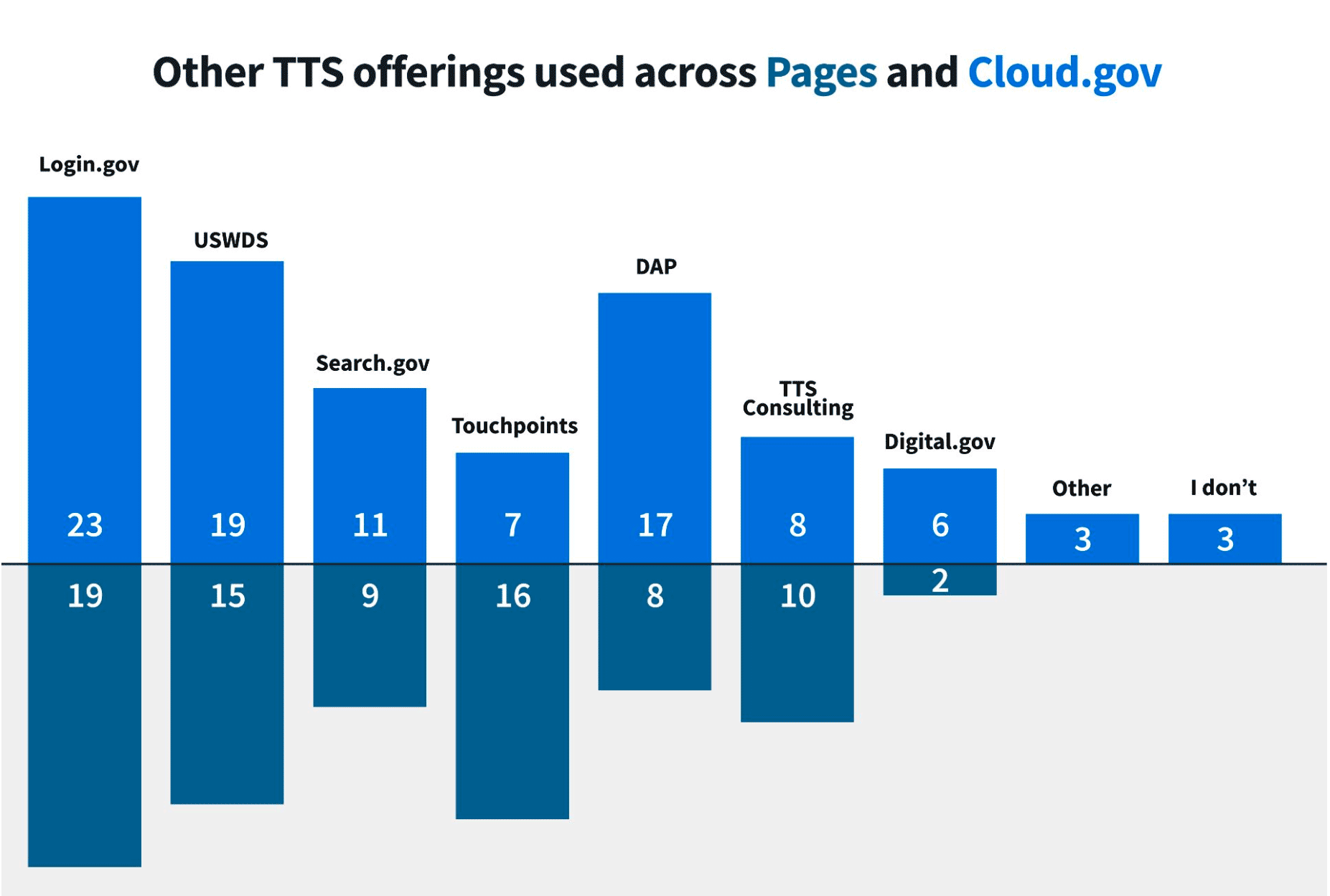
For years, our customers have experienced TTS and GSA as series of touchpoints across an ecosystem, while our reporting treated them as isolated relationships. The survey had drifted into a classic measurement trap:
“When a measure becomes a target, it ceases to be a good measure.”
— Goodhart’s Law
I still think that Cloud.gov's better participation rates were a win. However, validating a hypothesis and redesigning the instrument was the real outcome.
After sharing these results with the survey team, the executive responsible for the survey administration committed to incorporating a cross-product usage question into the default instrument for the following year, so that all programs could benefit.
Adjusting a single question in a yearly survey didn’t reorganize GSA's data reporting or TTS program collaboration overnight.
But it did make our customer overlap impossible to ignore. Programs have started to collaborate to better serve our customers. Leadership began incentivizing cross-product initiatives. In a period of significant organizational contraction, we realized new ways to support one another and our customers.
How we participated dramatically improved participation rates, which also improved our own signal quality. But more importantly, I redesigned the question that defined the data story, so we no longer had to compete for customer insight.